Normally, you'd use UML for the purpose you describe. UML basically breaks down into two types of diagrams: structural and behavioral.
Structural diagrams include: composition, deployment, package, class, object, and component. Behavioral diagrams include: sequence, state machine, communication, use case, activity, and interaction overview.
Depending on what you're trying to convey, you pick a few of these diagrams which best represent whatever you're trying to convey, and by so doing you allow the conversation to "move up a level". Instead of talking about methods, parameters, and code, you're talking about sequence of interactions, or static class dependencies, or whatever diagrams you choose to create.
I've attached an example of a sequence diagram (one of the behavior diagrams). I personally like the sequence diagram because it's right in the middle of the design artifact process -- roughly an equal number of diagrams depend on it as it expects as input. I find that the input diagrams are typically "understood" anyway, or the sequence diagram already implies their existence. However, sometimes I do both static class diagrams and sequence diagrams (one structural and one behavioral diagram).
http://omarfrancisco.com/wp-content/uploads/2011/07/sequencediagram.png
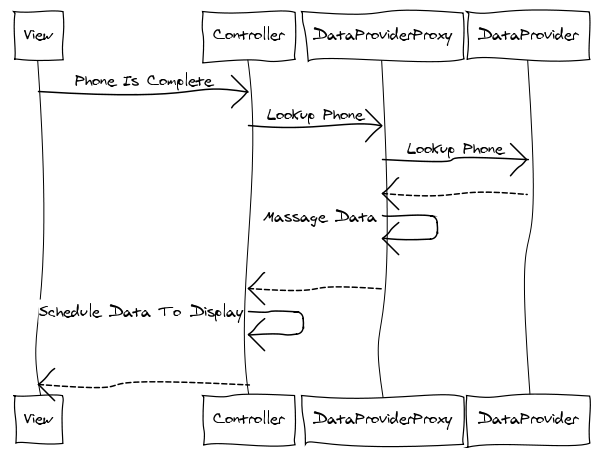
I have never seen this diagram before in my life, but I can tell a number of things about this system. There are four major components (the nouns in your system -- typically the classes): View, Controller, Data Proxy, and Data Provider. The arrows are "behaviors" or method invocations. A sequence diagram is basically good for showing a single important interaction between a bunch of components. You have one sequence diagram for each important flow through your system. I can tell from this particular diagram that "Controller" exposes a method called "phoneIsComplete()", which in turn depends on DataProviderProxy's "lookupPhone()" method, which in turn depends on DataProvider's "lookupPhone()" method.
Now, you might groan and think "uggg... this doesn't give me a big picture of the system -- it's just individual interactions through the system". Depending on the sophistication of the system, that might be a valid concern (simple systems can definitely get by with just a collection of sequence diagrams). So, we move over to the structural diagrams and we look at something like a static class diagram:
http://www.f5systems.in/apnashoppe/education//img/chapters/uml_class_diagram.jpg
Class diagrams help us figure out two important things: cardinality, and class relationship types. Classes can be related to one another in different ways: association, aggregation, and composition. Technically speaking, there's a difference between "static class relationships" and "instance relationships". However, in practice you see these lines blurred. The main difference is that static class relationships don't usually include cardinality. Let's look at the example above and see what we can see. First, we can see that "Special Order" and "Normal Order" are subtypes of "Orders" (inheritance). We can also see that one Customer has N Orders (which may be "Normal Orders", "Orders", or "Special Orders") -- the Customer object doesn't really know. We can also see a number of methods (in the bottom half of each class box) and properties (top half of each class box).
I could keep talking about UML diagrams for a long time, but this is the basics. Hopefully that helps.
TLDR; Pick one behavioral and one structural UML diagram, learn how to create it, and you'll accomplish what you're trying to accomplish.
It's all just software, so given enough effort it's possible ;-). In a language which supports a decent way of doing code analysis it should be feasible too.
As for the usefulness, I think it some automation around unit testing is useful to a certain level, depending on how it's implemented. You need to be clear about where you want to go in advance, and be very aware of the limitations of this type of tooling.
However, the flow you describe has a huge limitation, because the code being tested leads the test. This means an error in reasoning when developing the code will likely end up in the test as well. The end result will probably be a test which basically confirms the code 'does what it does' instead of confirming it does what it should do. This actually isn't completely useless because it can be used later to verify the code still does what it did earlier, but it isn't a functional test and you shouldn't consider your code tested based on such a test. (You might still catch some shallow bugs, like null handling etc.) Not useless, but it can't replace a 'real' test. If that means you'll still have to create the 'real' test it might not be worth the effort.
You could go slightly different routes with this though. The first one is just throwing data at the API to see where it breaks, perhaps after defining some generic assertions about the code. That's basically Fuzz testing
The other one would be to generate the tests but without the assertions, basically skipping step 10. So end up with an 'API quiz' where your tools determines useful test cases and asks the tester for the expected answer given a specific call. That way you're actually testing again. It's still not complete though, if you forget a functional scenario in your code the tool won't magically find it and it doesn't remove all assumptions. Suppose the code should have been if (handCardIndex > hand.getCapacity()) instead if >=, a tool like this will never figure that out by itself.
If you want to go back to TDD you could suggest test cases based on just the interface, but that would be even more functionally incomplete, because there isn't even code from which you can infer some functionality.
Your main issues are always going to be 1. Carrying errors in code over to the test and 2. functional completeness. Both issues can be suppressed somewhat, be never be eliminated. You'll always have to go back to the requirements and sit down to verify they are all actually tested correctly. The clear danger here is a false sense of security because your code coverage shows 100% coverage. Sooner or later someone will make that mistake, it's up to you to decide if the benefits outweigh that risk. IMHO it boils down to a classic trade-off between quality and development speed.
{kind=link}
{kind=link}
Best Answer
A standard way to publish (apart from the source code on GitHub) is to have formal JAR/WAR releases to Maven Central which many (Maven, Gradle, Ant/Ivy) build tools use to bring in libraries as a dependency. To do this, the best way is to go through the Nexus process.
It's also considered friendly to host those same JAR/WARs on a code hosting repo such as Sourceforge or GitHub.
In terms of your domain. I recommend you buy firstnamelastname.net/org/com and use that as your naming scheme (e.g. for me it's net.martijnverburg.foobar). Otherwise using the github domain as suggested by @Daniel Moura is a good one.
To publicise it, blog about it, twitter about it, submit it to hacker news, reddit, digg, slashdot, dzone, TSS, javaworld etc
HTH!