Normally, you'd use UML for the purpose you describe. UML basically breaks down into two types of diagrams: structural and behavioral.
Structural diagrams include: composition, deployment, package, class, object, and component. Behavioral diagrams include: sequence, state machine, communication, use case, activity, and interaction overview.
Depending on what you're trying to convey, you pick a few of these diagrams which best represent whatever you're trying to convey, and by so doing you allow the conversation to "move up a level". Instead of talking about methods, parameters, and code, you're talking about sequence of interactions, or static class dependencies, or whatever diagrams you choose to create.
I've attached an example of a sequence diagram (one of the behavior diagrams). I personally like the sequence diagram because it's right in the middle of the design artifact process -- roughly an equal number of diagrams depend on it as it expects as input. I find that the input diagrams are typically "understood" anyway, or the sequence diagram already implies their existence. However, sometimes I do both static class diagrams and sequence diagrams (one structural and one behavioral diagram).
http://omarfrancisco.com/wp-content/uploads/2011/07/sequencediagram.png
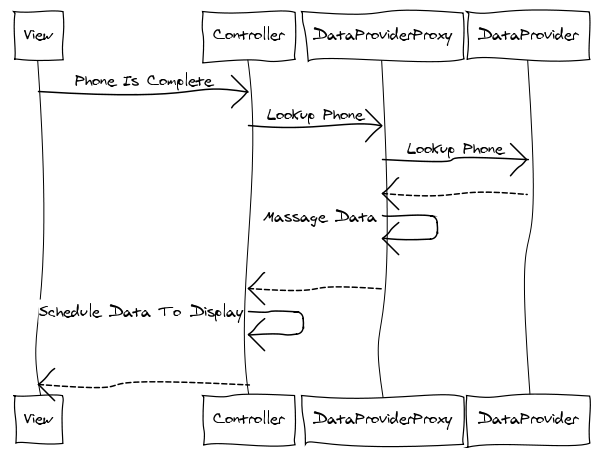
I have never seen this diagram before in my life, but I can tell a number of things about this system. There are four major components (the nouns in your system -- typically the classes): View, Controller, Data Proxy, and Data Provider. The arrows are "behaviors" or method invocations. A sequence diagram is basically good for showing a single important interaction between a bunch of components. You have one sequence diagram for each important flow through your system. I can tell from this particular diagram that "Controller" exposes a method called "phoneIsComplete()", which in turn depends on DataProviderProxy's "lookupPhone()" method, which in turn depends on DataProvider's "lookupPhone()" method.
Now, you might groan and think "uggg... this doesn't give me a big picture of the system -- it's just individual interactions through the system". Depending on the sophistication of the system, that might be a valid concern (simple systems can definitely get by with just a collection of sequence diagrams). So, we move over to the structural diagrams and we look at something like a static class diagram:
http://www.f5systems.in/apnashoppe/education//img/chapters/uml_class_diagram.jpg
Class diagrams help us figure out two important things: cardinality, and class relationship types. Classes can be related to one another in different ways: association, aggregation, and composition. Technically speaking, there's a difference between "static class relationships" and "instance relationships". However, in practice you see these lines blurred. The main difference is that static class relationships don't usually include cardinality. Let's look at the example above and see what we can see. First, we can see that "Special Order" and "Normal Order" are subtypes of "Orders" (inheritance). We can also see that one Customer has N Orders (which may be "Normal Orders", "Orders", or "Special Orders") -- the Customer object doesn't really know. We can also see a number of methods (in the bottom half of each class box) and properties (top half of each class box).
I could keep talking about UML diagrams for a long time, but this is the basics. Hopefully that helps.
TLDR; Pick one behavioral and one structural UML diagram, learn how to create it, and you'll accomplish what you're trying to accomplish.
{kind=link}
{kind=link}
Best Answer
I must admit, my heart contracted in stress when I read "...there are v1 and v2 packages in the code base..." Typically, versioned APIs are, well, versions of your code, and don't live side-by-side in your codebase.
How I've done it before is forking the repo. V1 sticks around for bug fixes until we can get everyone onto V2, and V2 is where all the new features go. Then in production, you deploy both codebases (either on different servers, or side-by-side), and your URL routing points to the appropriate instance.
This gives you the following benefits:
The only way someone writes code against the wrong API is if they're in the wrong repo (at which point, there's not much else you can do for that programmer).
You don't have to worry about backward compatibility in "shared" non-API classes (utility, service, DAO, what have you).
A deploy of one API does not impact the other.
Honestly? It provides a demonstrable business reason to abandon v1 as soon as possible (you can shut down the old server) that can clearly be explained to non-developers.
The downside is that the codebase is not shared, so changes in one that are "necessary" in the other must be ported. I don't see this as a big deal. It shouldn't happen that much (new features go into v2, not v1, by design), and any changes that truly need to be shared can be extracted into libraries or other services.